
HiDream-O1-Image on Hugging Face
If you’re thinking about purchasing a new GPU, we’d greatly appreciate it if you used our Amazon Associate links. The price you pay will be exactly the same, but Amazon provides us with a small commission for each purchase. It’s a simple way to support our site and helps us keep creating useful content for you. Recommended GPUs: RTX 5090, RTX 5080, and RTX 5070. #ad
The AI image generation space keeps evolving rapidly, and HiDream has now introduced a very different approach with HiDream.ai’s new model, HiDream-O1-Image.
Unlike most modern diffusion models that rely on latent-space processing and external VAEs, HiDream-O1-Image is designed as a pixel-space unified transformer model. In simple terms, the model works directly with raw pixels instead of compressing images into latent representations first.
That architectural change has made the model one of the most discussed AI releases in the Stable Diffusion community this week.
Here is the post from @ArtificailAnlys. HiDream-O1-Image (codename: Peanut) is ranked No. 8.

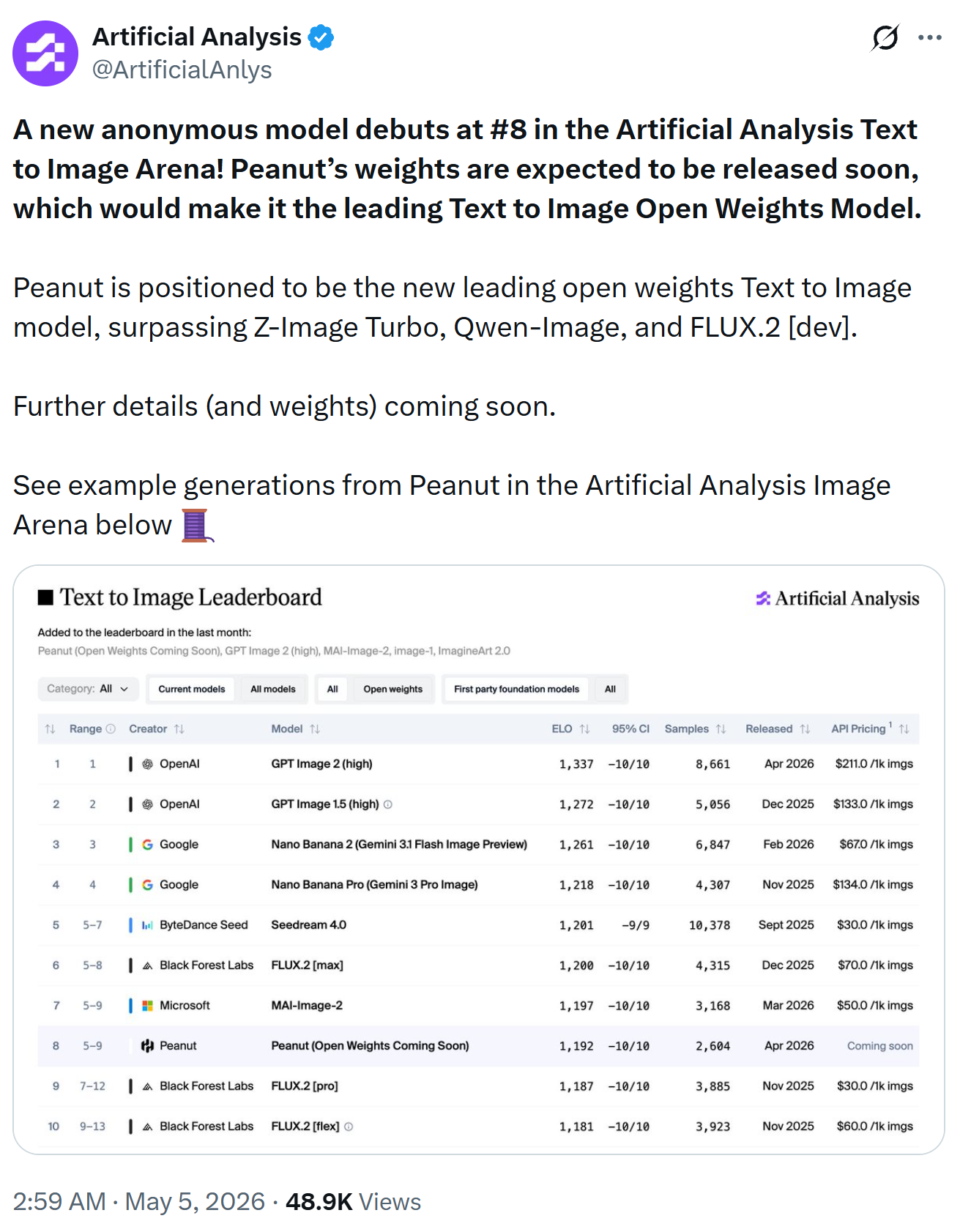
What Is HiDream-O1-Image?
According to the official model description, HiDream-O1-Image is an 8B parameter unified image foundation model capable of:
- Text-to-image generation
- Image editing
- Subject-driven personalization
- Storyboard generation
- Long-text rendering
- High-resolution image synthesis up to 2048×2048
The model uses what HiDream describes as a “Pixel-level Unified Transformer (UiT)” architecture that eliminates the need for separate VAEs and disconnected text encoders.
This is a major departure from common pipelines used by models like FLUX, SDXL, and many other diffusion systems.
Why the “No VAE” Design Matters
Most AI image generators today work in latent space. They first compress images using a Variational Autoencoder (VAE), perform diffusion in compressed form, and then decode the result back into pixels.
HiDream-O1-Image skips that entire process.
Potential advantages include:
- Simpler architecture
- Fewer pipeline components
- Better consistency between text and image generation
- Native high-resolution output
- Potentially improved text rendering
The model also combines text understanding, reasoning, layout planning, and image generation into a single system.
Built-In Prompt Reasoning
One of the more interesting features is HiDream’s internal “reasoning-driven prompt agent.”
Community members discovered that the model internally expands prompts before generation using a creative-director style system prompt. The system attempts to infer scene details, composition, spatial relationships, and missing visual information automatically.
This approach is somewhat similar to prompt enhancement systems used by commercial image generators, but integrated directly into the model workflow.
Available Versions
Currently, there are two main public releases:
- HiDream-O1-Image
- HiDream-O1-Image-Dev
The Dev version is intended to run faster with fewer steps, while the full version targets maximum quality.
Community reports suggest:
- Full model: around 50 steps
- Dev model: around 28 steps
Community Reactions So Far
The release has generated a lot of attention across Reddit and Hugging Face, but reactions have been mixed.
Some users praised:
- The new architecture
- Fast 2048×2048 generation
- Strong prompt understanding
- The ambitious unified design
Others reported issues such as:
- Plastic-looking skin
- Soft image detail
- Banding artifacts
- Inconsistent output quality
- Poor image editing performance in some cases
Several users also noted that newer code updates appear to improve performance and reduce some earlier issues.
As with many newly released AI models, the ecosystem and workflows will likely improve rapidly over the coming weeks.
Performance and Hardware
HiDream-O1-Image is relatively lightweight compared to some massive modern image models at 8B parameters, but it still requires substantial GPU resources for high-resolution generation.
Some community tests reported:
- 2048×2048 generation in around 20 seconds on an RTX 4090 using FP8 workflows
- Faster inference after recent dtype fixes
- Heavy VRAM usage for full-quality generation
Support for ComfyUI workflows is still evolving.
Relationship to HiDream-I1
HiDream-O1-Image builds upon the company’s earlier work with HiDream-I1, a 17B sparse diffusion transformer model released in 2025.
HiDream-I1 focused on:
- High image quality
- Strong prompt following
- Sparse DiT efficiency
- Open-source accessibility
The project also expanded into:
- HiDream-E1 for image editing
- HiDream-A1 for interactive image creation workflows
Examples


Final Thoughts
HiDream-O1-Image is one of the more experimental open-source image model releases in recent months. Its pixel-space unified architecture represents a significant shift away from traditional latent diffusion pipelines.
While early community feedback is divided regarding image quality, the model introduces several technically ambitious ideas:
- Native pixel-space generation
- Unified multimodal architecture
- Integrated prompt reasoning
- Multi-task image workflows
- Native high-resolution synthesis
Whether it becomes a major competitor to FLUX, SDXL, or future DiT models will depend on how quickly the ecosystem matures and how much the image quality improves with updates, fine-tuning, and optimized workflows.
For AI creators and researchers, though, HiDream-O1-Image is definitely a model worth watching.
Leave a Reply