
deforum-art has published an extension to incorporate ModelScope text to video(text2video) with Automatic1111’s Stable Diffusion Web UI. I am going to show you how to install the use this extension in this article.
If you’re thinking about purchasing a new GPU, we’d greatly appreciate it if you used our Amazon Associate links. The price you pay will be exactly the same, but Amazon provides us with a small commission for each purchase. It’s a simple way to support our site and helps us keep creating useful content for you. Recommended GPUs: RTX 5090, RTX 5080, and RTX 5070. #ad
Enable the Extension
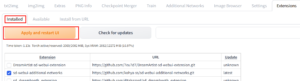
- Click on the Extension tab and then click on Install from URL.
- Enter https://github.com/deforum-art/sd-webui-modelscope-text2video in the URL box and click on Install.

- Click on Installed and click on Apply and restart UI.
- Go to your stable-diffusion-webui/models folder and create a folder called ModelScope and then create a folder called t2v under ModelScope. This is your models folder for text2video. The path for this folder is stable-diffusion-webui/models/ModelScope/t2v .
- There are two sets of models that you can use. Original models are bigger in size and require more VRAM to use. Download the models and the configuration file and put them in the folder created earlier. Note that for the configuration file, you will have to click on </> raw to get the file.
Original models
Pruned and half precision models - Restart webui

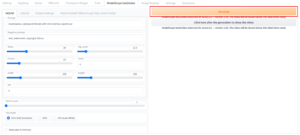
text2video Example
- Click on ModelScope text2Video tab and enter the prompt as you like. Click on Generate to start the process.
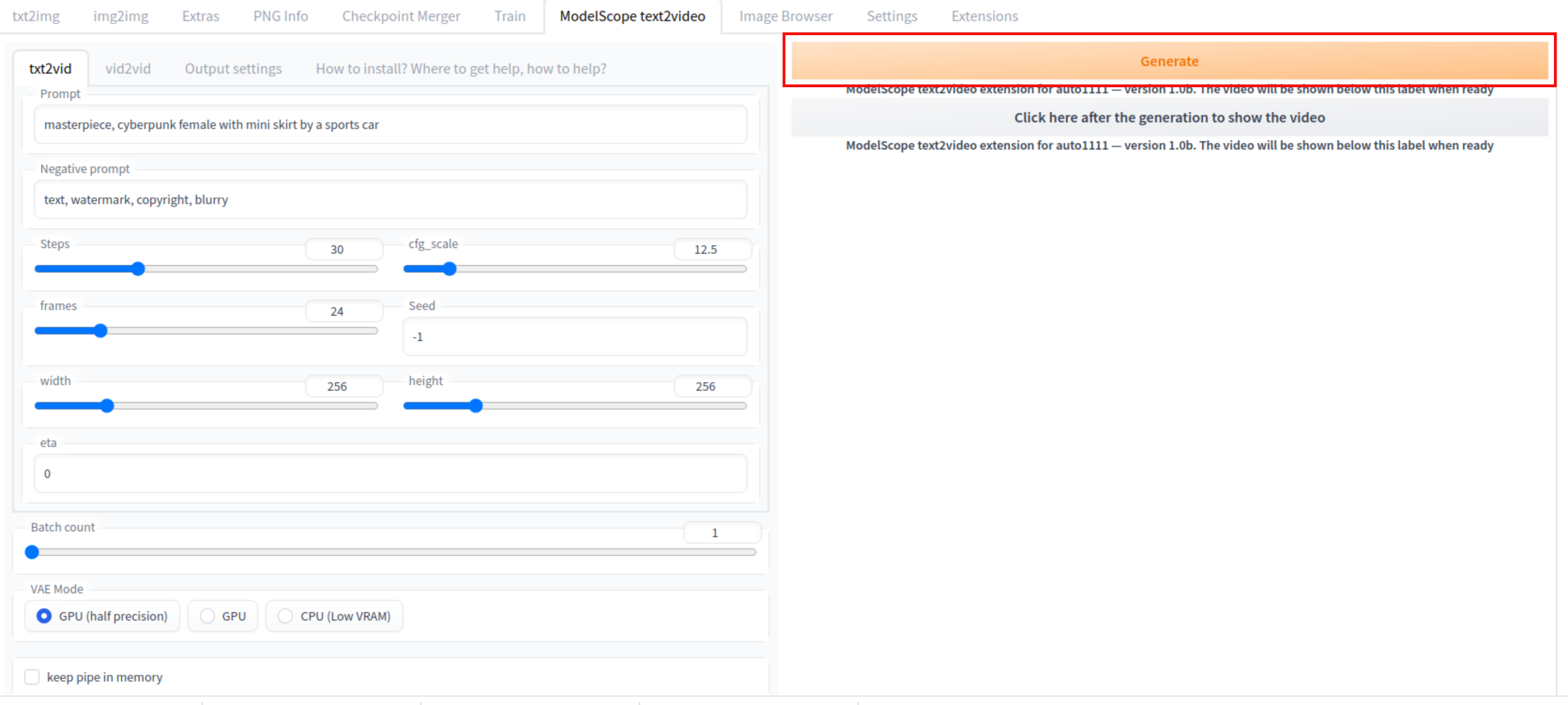
- The interface does not tell you when it’s done. You will have to look at the console window to see if it’s done generating. When it’s done, click on Update the video to see the generated video. The generated video is under stable-diffusion-webui/outputs/img2img-images/text2video-modelscope/
Some observations about this extension:
- My GPU with 12GB VRAM can generate up to 384×384 videos.
- If you enter the height and weight manually, it might not work. Instead, use the up and down arrow to adjust the height and weight.
- I have tried different resolutions, but it seems that 256×256 gives the best results.
- If you want to generate videos with a human subject, you can try this prompt.
Prompt: ultra realistic photo portrait of your_subject_here ,beautiful symmetrical face, nonchalant kind look, realistic round eyes, tone mapped, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, dreamy magical atmosphere, art by artgerm and greg rutkowski and alphonse mucha, 4k, 8k
Negative prompt: frame, border, ugly, fat, overweight, (long neck), bad quality, error, blurry, blurred, high contrast, ((dyed hair)), two heads, multiple heads, two faces, multiple faces, multiple people, group of people - Most videos have the shutterstock watermark and cannot be removed by negative prompt.
I have created a YouTube short video as a demo.
niiiiiiiice shots mate, I got 8gb rtx 3070 and getting nowhere near that, how do you prompt it to run smooth coherent concatenation of consequent frames?
You just have to try a lot. You can try the prompt in the article and modify it to suit your need. Good luck.
oops, think the extension install broke my SD: ModuleNotFoundError: No module named ‘tqdm.auto’, froze on the reset and then this now lol